华体会电竞
专业的铝圆片生产者
先进高效的生成铝圆片生产设备,月产量1500吨!

时间:2024-06-13 23:02:30 来源:铝圆片
计算机的兴起不仅源于技术上的成功,也归功于经济力量为其提供的支持。Bresnahan和Trajnberg创造了通用技术(general purpose technology, GPT)一词用于诸如计算机这类的,这一些产品具有广泛的技术适用性,并且在数十年间其产品改进和市场增长可以相互促进。但是,他们还预测到GPT可能会在其生命周期的后期遭遇挑战:随着进展放缓,在一些特定的市场定位上,其他技术能取代GPT并破坏了这一经济持续增长的周期。今天,我们也可以观察到这样的转变:由于中央),虽然它能完成的工作比传统的通用处理器要少,但是在实现特定功能的时候表现出了更高的性能。包括
在这种背景下,我们现在能更加明确这篇文章的主题:“The Decline of Computersas a General Purpose Technology”。我们并不是说计算机将失去技术能力从而“忘记”怎么样做一些计算,我们的观点是,在快速改进通用处理器的基础上,零散的经济周期正在慢慢地取代使用通用计算平台的经济周期,而在这种零散的周期中,经济学将用户推向由专用处理器驱动的多样化计算平台。
这种碎片化意味着部分计算将以不同的速度进行,这对于在“快车道”中运行的应用来说是一件好事情,在这种情况下,更新迭代保持迅速的状态,但是对那些不再受益计算能力提升的应用来说,他们也因此被分配为“慢车道”。这种转变也可能减慢计算机改进的总体步伐,从而危及这一重要领域的经济贡献。
早期-从专用到通用。早期的电子科技类产品并不是可以执行许多不同计算的通用计算机,而是专用于完成一项任务且仅有一项任务的专用设备,例如收音机或电视机。这种专用的设备具备了以下优点:设计复杂度可控、处理器高效、工作更快、功耗更低,而缺点就在于专用处理器的应用场景范围也更窄。
早期的电子计算机,甚至那些被设计为“通用”的计算机,实际上都是为特定算法量身定做的,很难适应其他算法。例如,1946 ENIAC虽然在理论上是通用计算机,但它大多数都用在计算artillery range tables,哪怕需要略微不同的计算,都必须重新手动连接计算机来改变硬件设计。解决此问题的重点是要设计出可以存储指令的新计算机体系结构,这种体系结构使计算机灵活性更好,能够在通用硬件而非专用硬件上执行许多不同的算法。这种“冯·诺依曼架构”非常成功,目前,它依然是几乎所有通用处理器的基础。
通用处理器的崛起。许多技术引入市场时便经历了能够在一定程度上帮助它们发展的良性循环(图1a)。最初,使用者购买该产品,从而为产品升级更新提供了资金支持。随着产品的改进,慢慢的变多的消费者会去购买它,这为下一轮的改进提供了资金,依此类推。然而对于许多产品而言,由于产品改进变得过于困难或市场增长停滞,这种循环从中短期来看在逐渐减弱。
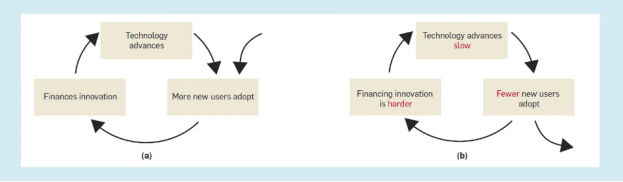
在通用处理器发展的几十年里,GPT一直能够继续受益于这一良性经济周期。其市场已从军事、航天等领域发展到全球使用的20多亿台PC,这种市场增长推动了慢慢的变多的投资来实现处理器的改进。例如,英特尔过去十年在研发和制造设备上花费了1830亿美元,这部分的投资已经带来了巨大的回报:据估计,自1971年以来CPU性能已经提高了约40万倍。
另一种选择:专用处理器。通用处理器一定要能很好地进行多种不同的计算,这导致设计上不得不做出折衷,虽然有许多运算能够迅速完成,但并没有哪一个达到最优。对那些适合专用处理器的应用,这样的折衷方案会导致很高的性能损失。这些应用的运行具有一些特征:
在上述的情况下,专用处理器(例如,ASIC)或异构芯片的专用部件(例如,I.P. block)能更好地执行运算,因为这些硬件能够准确的通过应用量身定制。
在对典型CPU(主要的通用处理器)和典型GPU(最常见的专用处理器)作比较时,能够准确的看出专用性在某一些程度上改变了处理器设计变化程度(见附表)。
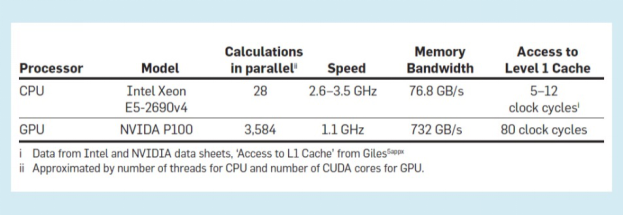
GPU的工作速度较慢,约为CPU的三分之一,但在每个时钟周期中,它可以并行执行比CPU多100倍的计算。这使得对于并行性很强的任务,它的运算比CPU快得多,反之,对那些并行性很小的任务,GPU的工作速度则会慢于CPU。
GPU的内存带宽通常是GPU的5-10倍(带宽决定一次可以传输多少数据),但访问这一些数据的时间延迟却要长得多(至少是最近内存时钟周期的6倍),这使得GPU在可预测的计算(从内存中所需的数据可以被预测并在适当的时间传输到处理器)方面做得更好,而在不可预测的计算上表现不佳。
对于与专用硬件非常匹配的应用程序,GPU在性能上的提高可能是巨大的。例如,2017年,GPU的领先制造商NVIDIA估计,深度学习(AlexNet与Caffe合作)在GPU上的工作速度较CPU提高了35倍以上,现今,该速度甚至更高。
专用处理器的另一个重要优点是,在进行相同的计算时它的能耗更低。这对于受电池使用寿命限制的应用(如手机物联网设备)和需要大规模计算的应用(云计算/数据中心、超级计算)尤为重要。
截至2019年,十大最省电超级计算机中有九台使用了NVIDIA的GPU。
专用处理器也有致命的缺点:它们能运行的程序范围非常有限,也很难编程,并且常常要一个运行操作系统的通用处理器来控制它们中的一个或多个。设计生产专用硬件也可能十分昂贵。对于通用处理器,其固定成本(也称为非经常性工程成本(NRE))会均摊到大量芯片上。相比之下,专用处理器的市场通常要小得多,因此每个芯片的固定成本更高。截至2018年,使用先进的技术制造带有专用处理器的芯片的总成本约为8000万美元,而使用老一代的技术能将成本降低到3000万美元左右。
尽管专用处理器有很多优点,但是它们的缺点依然非常致命,在过去的几十年中,出GPU以外,其他专用处理器就没有被采用。专用处理器的技术仅仅采用在那些性能提升最重要的领域,包括军事应用、游戏和密码货币挖掘领域。但这种情况正在开始改变。
专用处理器的现状。包括PC、移动电子设备、物联网(IoT)和云计算/超级计算在内的所有主要计算平台的专用性都慢慢的变强。其中,PC仍然是通用性最强的。相比之下,由于电池使用寿命,能源效率在移动和物联网中更重要,因此,智能手机芯片上的许多电路(例如RFID)和传感器均使用专用处理器。
云计算/超级计算也变得更趋向于专用性。例如,2018年,最大的500台超级计算机的新增产品首次从专用处理器获得了比通用处理器更高的性能。
国际半导体技术蓝图(ITRS)的行业专家协调了保持摩尔定律发展所需的技术改进,他们在最终报告中隐含地表达了这种向专用性的转变。他们承认,不应再用传统的“一刀切”的方法去确定设计的基本要求,相反,应针对特定应用量身定制。
下一部分将探讨所有主要计算平台向专用处理器的转变,将对生产通用处理器的经济性产生的影响。
支持GPT的良性循环来自一系列相辅相成的技术和经济力量。但不幸的是,它同样也会带来反作用:如果这个周期中的某个部分中的改进进程变慢,那么别的部分的改进也会相应变慢。我们将此对立点称为“fragmenting cycle”,因为它有可能将计算碎片化为一系列松散相关的部分,这些部分以不同的速度推进。
这个周期背后的原理很简单:如果技术进步缓慢,那么新用户的人数就会减少,但假如没有这些新用户更好的提供的市场增长,那么改进该技术所需的不断上涨的成本可能变得令人望而却步,从而减缓了进展。因此,在这种协同反应之下,每个部分都会逐渐增强碎片化。
下面,我们将详细分析该循环三个部分中每一个的状态,从而得到“碎片化慢慢的开始”已然开始的结论。
技术进步缓慢。我们用两个关键指标来衡量处理器的改进速度:“性能“”和“每美元性能”。从长期数据看,这两个指标均迅速提高,还在于晶体管的小型化致使每个芯片的晶体管拥有更高的密度(摩尔定律)和更快的晶体管开关速度(Dennard缩放比例定律)。不幸的是,由于技术原因,制造商已达到了现有材料和设计所能做的物理极限,Dennard 缩放比例定律于2004/2005年终结,摩尔定律也慢慢变得难维持,这些技术极限需要付出极大的努力才能克服。在这样的一个过程中,可以明显看到小型化所带来的“性能”和“每美元性能”的提升正在放缓。
从Hennessy和Patterson对SPECInt进度的描述(图2 a)以及美国劳工统计局的生产者价格指数(图2 b)能够准确的看出,通用计算机性能的提升显著放缓。从这些角度来看,如果“每美元性能”每年以48%的速度提高,那么10年后它的效率将提高50倍。相比之下,如果每年仅以8%的速度提高,那么在10年内,它只会提高2倍。
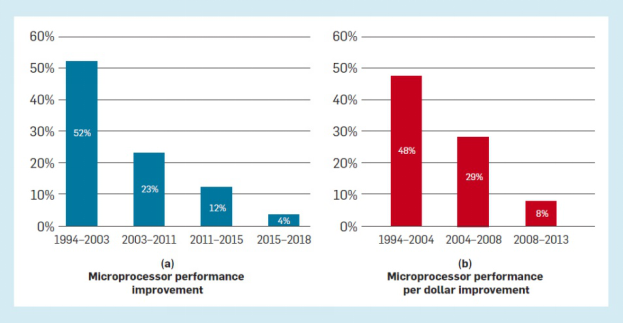
图2.微处理器的改进率,根据以下标准衡量:(a)SPECint基准上的年度性能改进,(b)质量调整后的年度价格下降。
新用户减少。 随着通用处理器的提升的步伐放慢,新功能的开发也会减少,因此导致客户没有更换计算设备的医院。英特尔首席执行官Krzanich在2016年证实了这一点,称PC的更换率已从每4年一次提高到每5-6年一次。有时,用户甚至会跳过很多代处理器的升级,因为觉得它们不值得更新。在其它平台上也是如此,例如2014年美国智能手机平均每23个月进行一次升级,但到2018年则延长到31个月。
用户从通用处理器向专用处理器的转移是我们关于计算碎片化的论点的核心,因此我们将对其进行详细讨论。假设现在有一个用户,他既能够正常的使用通用处理器也能够正常的使用专用处理器,但希望以最低的成本得到最佳性能。图3(a)和图3(b)给咱们提供了直观的分析,两幅图都显示了通用处理器和专用处理器随时间的性能提升情况,但是通用处理器的改进速度在两幅图中却不一样。在所有情况下,我们都假设选择了时间T,那么专用处理器的高价格将由一系列经过改进的通用处理器的成本所平衡,这在某种程度上预示着两条曲线在成本上是相等的,因此,优良的“性能”也代表着同样优越的“每美元性能”,这也是我们大家都认为专用处理器在最近一段时间内具有稳定的性能的原因。(在专用处理器升级这一点上,它也将获益于通用处理器受益的改进,并且用户将再次重复相同的决策过程。)
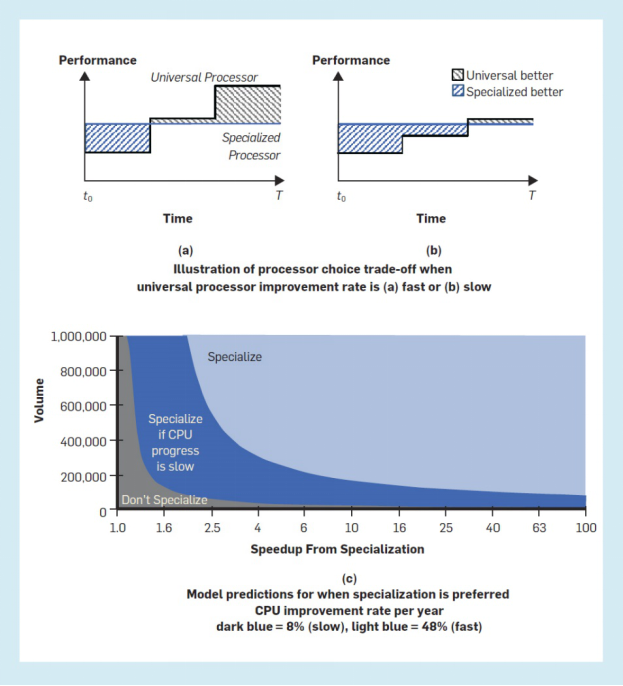
图3. 最佳处理器的选择取决于专用处理器带来的性能提升以及通用技术的提高速度。
如果专用处理器能够给大家提供更大的性能初始收益,那么它会更具吸引力。但是,如果通用处理器的改进从图3(a)中的加快速度进行发展变成图3(b)中的缓慢发展,专用处理器也变得更具吸引力。我们通过考虑两条时间路径中的哪一条可提供更多收益来进行建模。也就是说,如果:
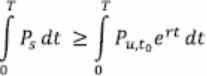
式中,通用处理器和专用处理器在时间T上可提供性能分别为Pu和Ps,通用处理器的性能提升速率为r。我们在在线附录(org/10.1145/3430936)中展示了该模型的完整推导。该推导让我们从数学上估算专用处理器抵消高成本所需要的优势的量(图3 c 中显示,CPU的年改进率从48%降低到8%)。
毫无疑问,专用处理器在提供更大的加速比或将其成本均摊到更大的数量时将会更具吸引力。但是,随着通用处理器改进的步伐,当专用性变得着迷时,这些临界值将发生明显的变化。重要的是,因为我们假设总体上专用处理器与通用处理器之间的进度不一样,即假定所有处理器都可使用当前最先进的制造技术,所以将不会产生上述的影响。相反,它的出现是因为必须分摊专用处理器高昂的每单位NRE(一次性工程费用),以及在此期间与升级通用处理器相比之下的优越性。
一个数据清楚地表明了这一变化的重要性。在摩尔定律的顶峰时期,当每年的改进速度为48%时,即使专用处理器的速度比通用处理器快100倍,也就是
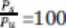
(这是一个巨大的差距),为了获得投资回报,还需要大约8.3万的生产量。在另一个极端,如果性能优势仅为2倍,则需要生产数量要达到约1,000,000才能使专用性处理器更具吸引力。这些结果清楚地说明了为什么在摩尔定律的鼎盛时期,专用处理器的生产商很难进入市场。
但是,如果个人会使用8%(2008-2013年的增长率)重复处理器选择计算,那么这些结果将发生显着变化:对于速度提高100倍的应用,所需的处理器数量从83,000降至15,000,对那些提速2倍的应用,数量则从1,000,000下降到81,000。因此,在通用处理器的更新进度变慢之后,更多的应用就会转向专用处理器。
更难为创新筹集资金。2017年,半导体行业协会估计,为下一代芯片建造和配备制造设施(“ fab”)的成本约为70亿美元。“下一代”是指芯片进一步小型化(或称进程“节点”)。
用于芯片制造设施的成本的投资必须由它们产生的营收来平衡。2016年,该行业3430亿美元的年收入中,多达30%来自尖端芯片,虽然收入十分可观的,但是成本也在增长。在过去的25年中,受到光刻成本的影响,建造领先的晶圆厂的投资(如图4a所示)每年增长11%。将过程开发成本包括在此估算中,将进一步使成本每年增长至13%(根据Santhanam等在2001年至2014年间进行的测算)。讽刺“摩尔第二定律”的芯片制造商都知道:芯片厂的成本每四年翻一番。
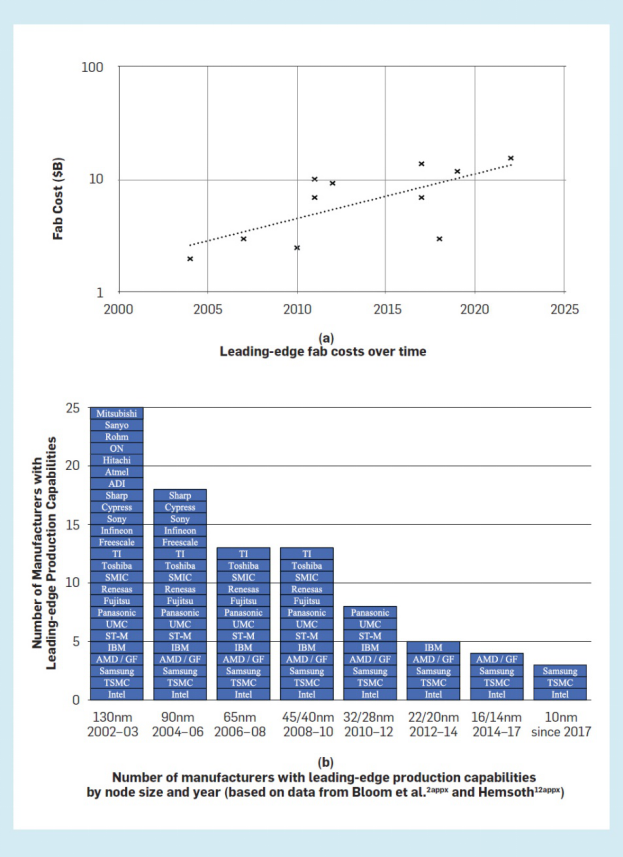
长期来看,如此快速的固定成本增长对单位成本的影响仅有部分能被强劲的整体半导体市场增长所抵消(1996-2016m年复合增长率为5%),这使半导体制造商能够在更大的数量上分摊固定成本。固定成本每年增长13%与市场每年增长5%之间的巨大缺口中的剩余部分,可能将导致竞争力较弱的参与者退出市场,而其余参与者则通过大量筹码来摊销其固定成本。
如图4(b)所示,该行业确实存在着巨大的整合,生产领先芯片的公司慢慢的变少。从2002/2003到2014/2015/2016,拥有领先晶圆厂的半导体制造商数量已从25家减少到只有4家:英特尔、TSMC、三星和格罗方德。而格罗方德近期宣布,他们将不会继续下一个技术节点的开发。
我们发现这种合并有很大的可能性是由于固定成本快速上升且市场规模仅适度增长带来的经济恶化所致。通过一些计算,能够准确的看出市场整合在多大程度上改善了半导体行业额经济性。如果将市场平均分配给不同公司,则意味着平均市场占有率将从2002/2003年的
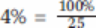
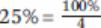
。以复合年增长率表示,这将是14%。这在某种程度上预示着生产商能够最终靠市场增长并占有现有工厂的市场占有率(13%《5%+ 14%)来弥补晶圆厂建设日益恶化的经济状况。
实际上,市场不是平均分配的。英特尔在市场上占有主导地位,结果,英特尔也无法以这种方式抵消固定成本的增长。实际上,在过去十年中,英特尔固定成本与其可变成本的比率已从60%上升到100%以上,这一点尤为引人注目,因为近年来,英特尔放慢了发布新节点大小的步伐,预计这将降低他们做固定成本投资的步伐。
市场整合抵消固定成本增长的能力只能持续一段时间。如果我们预测当前趋势,那么到2026年至2032年(取决于市场增长率),领先的半导体制造将只能支持单个垄断制造商,并且每年为新工艺节点建造新设施的固定成本将等于年度行业收入。需要说明的是,我们的论断并不是说这要在2020年代末成为现实,而是强调当前的趋势会无法持续,并且在大约10年内制造商将被迫大大放慢新工艺节点的发布速度,并寻找其他控制成本的方法,这两者都会进一步减缓通用处理器的提升进度。
碎片化循环。碎片化循环周期的三个部分中,在每个部分之间都会相互增强的情况下,我们大家都希望看到慢慢的变多的用户能看到通用处理器的及其微小的改进,从而转为关注专用处理器。对那些有极高需求和很适合专业化计算(例如深度学习)的人,这将意味着性能上巨大的提高。对其他人来说,专用化将不是一个合适的选择,它们将会留在通用处理器上,并且发展速度会慢慢的慢。
谁会去做专用处理器。如图3(c)所示,专用处理器将用于更换后获得大幅度提速的应用场景,并且需要足够的需求量才能证明这一开销是合理的。据此标准,大型科技公司成为最早一批投资专门处理器的公司也并不奇怪,例如谷歌、微软、百度和阿里巴巴。与仍可受益于大范围的应用程序的GPU专业化或对大多数用户有价值的加密电路中的专业化不同,我们期望未来的专业化会更窄,因为仅需少量处理器即可使收益更可观。
我们还期望大量使用这一些专用处理器的人,并非是专用处理器的设计者,而是像将GPU用于深度学习运算的人一样,用新的硬件来设计算法。
先前,我们描述了四个特征,这些特征使得使用专用处理器可以加快计算速度。假如没有这些特性,那么专门化只能带来最小的性能提升(如果有的话)。一个重要的例子是数据库。正如我们采访的一位专家告诉我们的那样:在过去的几十年中,很明显,专用于数据库的处理器可能很有用,但是数据库所需的计算不适合采取了专用处理器。
第二类将无法用专用处理器的是那些需求不足以证明前期固定成本合理的处理器。 正如我们通过模型得出的那样,需要数以千计的处理器市场来证明专用化的合理性。这可能会影响那些在小范围内进行密集计算的人(例如,研究科学家进行罕见的计算)或那些计算随时间而快速变化并因此需求迅速消失的人。
可能不会用专用处理器的第三组是那些没有单个用户有充足需求且协调困难的群体。 例如,即使成千上万的小用户共同拥有足够的需求,也很难使他们共同为生产专门的处理器做出贡献。云计算公司能够最终靠资助创建专用处理器,然后将其租出来来解决这一问题。
技术进步会让我们摆脱困境吗?为了使我们回到一个收敛的周期,在该周期中,用户将切换回通用处理器,这需要性能和/或每美元性能的快速提高。但是技术趋势却指向相反的方向。例如,在性能方面,预计微型化的最终好处将是价格溢价,并且仅可能由重要的商业应用来支付。甚至存在一个疑问——是否将完成所有剩余的、在技术上可行的小型化。Gartner预测,到2026年5nm量产时将会有更多的小型化,而台积电(TSMC)最近宣布了一项投资195亿的 2022年达到3nm的计划,但我们在本研究中采访的许多受访者对进一步的小型化是否值得持怀疑态度。
其他技术改进是不是能够恢复通用处理器改进的步伐?当然,有关此类技术的讨论很多:量子计算,碳纳米管,光学计算。不幸的是,专家们预计,至少要再过十年,工业界才能设计出一种范围更广的量子计算机,进而有可能替代传统的通用计算机。可能具有更广阔前景的其他技术仍将需要大量资金来开发并投放到市场。
传统意义上,计算的经济性是由通用技术模型驱动的,通用处理器的提升越好,那么市场增长就会加大对其投资,从而逐步推动它们的改进。几十年来,GPT的这种良性循环使计算成为经济稳步的增长的最重要驱动力之一。
本文提供的证据说明,这种GPT周期已被碎片化的周期所取代,这些碎片化的周期导致了计算速度的增长缓慢和用户的分裂。我们展示了fragmenting cycle的三个部分,它们中的每一个都已经在进行中:通用处理器的改进率已然浮现了急剧且一直增长的放缓;购买通用处理器和专用处理器之间的经济权衡已急剧转向专用处理器;而且制造更好的处理器的固定成本一直上升,将无法再由市场增长率来弥补。
总而言之,这些发现清楚地表明,处理器的经济情况已发生了巨大变化,将计算推入了截然不同的专门领域,并且彼此之间提供的利益也慢慢变得少。而且,由于此循环是自我增强的,因此它将永久存在,从而进一步碎片化通用计算。最终,将会拆分出更多的专用的应用,通用处理器的改进速度将进一步放慢。
本调了经济学推动计算方向的重大转变,并对那些想要计算碎片化的人们提出了挑战。
文章出处:【微信号:半导体科技评论,微信公众号:半导体科技评论】欢迎添加关注!文章转载请注明出处。
机在性能上实现了重大突破,相较于MACBOOK AIR M3,速度提升了惊人的58%。这一创新之举,不仅彰显了微软在AI领域的深厚实力,更为未来的
集成电路(IC)是在电子领域中常见的两种类型的电路。它们之间的区别大多数表现在其设计、应用和特点方面。本文将详细探讨
集成电路(ASIC)是两种不一样的集成电路,它们在设计和用途上有很大的不同。以下是
集成电路(Application Specific Integrated Circuit,简称ASIC)是一种根据特定需求而设计的集成电路。与
集成电路是两种不一样的集成电路。虽然它们都是由大量的电子元件和电路组成,但其设计、制造和应用方面存在非常明显差异。本文将详细介绍
集成电路(Application Specific Integrated Circuit,ASIC)是根据特定应用需求而设计和制造的集成电路。与
变频器是用于驱动电机的两种不一样的变频器。虽然它们都能控制电机的电压和频率,但在其功能、性能和适合使用的范围方面存在着一些差异。 一
存在吗? /
时器控制 I/O 显示 LED 的各种表示方式,包括 RGB 模糊、闪亮和
时器控制 I/O 显示 LED 的各种表示方式 PWM, 但当LED比PWM多时, 时间
MCU产品家族增加新成员 /
模式 /
时器包含一个系统计数器(System Counter)和每个处理器核自己的计时器(per-core timer),如下图。图中的PE(Processor Element)代表处理器核。
时器 /
GPU相关IP设计 /
H5U-A8 PLC通过HT3S-EIS-COP网关 与汇川660C伺服通讯
用于评估DA14695 SmartBond™模组的DA14695MOD-00DEVKT-P低功耗蓝牙开发套件
【紫光同创盘古PGX-Nano教程】——(盘古PGX-Nano开发板/PG2L50H_MBG324第八章)密码锁实验例程






